我的MySQL版本是8.0.17
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
MySQL [mydb]> SHOW VARIABLES LIKE '%version%';
+--------------------------+-------------------------------+
| Variable_name | Value |
+--------------------------+-------------------------------+
| immediate_server_version | 999999 |
| innodb_version | 8.0.17 |
| original_server_version | 999999 |
| protocol_version | 10 |
| slave_type_conversions | |
| tls_version | TLSv1,TLSv1.1,TLSv1.2,TLSv1.3 |
| version | 8.0.17 |
| version_comment | Source distribution |
| version_compile_machine | x86_64 |
| version_compile_os | Linux |
| version_compile_zlib | 1.2.11 |
+--------------------------+-------------------------------+
11 rows in set (0.01 sec)
建表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
DROP TABLE IF EXISTS CHARTEVENTS;
CREATE TABLE CHARTEVENTS (
ROW_ID INT UNSIGNED NOT NULL PRIMARY KEY,
SUBJECT_ID MEDIUMINT UNSIGNED NOT NULL,
HADM_ID MEDIUMINT UNSIGNED,
ICUSTAY_ID MEDIUMINT UNSIGNED,
ITEMID MEDIUMINT UNSIGNED NOT NULL,
CHARTTIME DATETIME NOT NULL,
STORETIME DATETIME,
CGID SMALLINT UNSIGNED,
VALUE TEXT, -- max=91
VALUENUM DECIMAL(22, 10),
VALUEUOM VARCHAR(50), -- max=17
WARNING TINYINT UNSIGNED,
ERROR TINYINT UNSIGNED,
RESULTSTATUS VARCHAR(50), -- max=6
STOPPED VARCHAR(50) -- max=8
)
CHARACTER SET = UTF8;
查看表的结构
- 使用
DESCRIBE:1
DESCRIBE CHARTEVENTS;
得到的结果为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
MySQL [mydb]> DESCRIBE CHARTEVENTS; +--------------+-----------------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-----------------------+------+-----+---------+-------+ | ROW_ID | int(10) unsigned | NO | PRI | NULL | | | SUBJECT_ID | mediumint(8) unsigned | NO | MUL | NULL | | | HADM_ID | mediumint(8) unsigned | YES | | NULL | | | ICUSTAY_ID | mediumint(8) unsigned | YES | | NULL | | | ITEMID | mediumint(8) unsigned | NO | MUL | NULL | | | CHARTTIME | datetime | NO | MUL | NULL | | | STORETIME | datetime | YES | | NULL | | | CGID | smallint(5) unsigned | YES | MUL | NULL | | | VALUE | text | YES | MUL | NULL | | | VALUENUM | decimal(22,10) | YES | | NULL | | | VALUEUOM | varchar(50) | YES | | NULL | | | WARNING | tinyint(3) unsigned | YES | | NULL | | | ERROR | tinyint(3) unsigned | YES | MUL | NULL | | | RESULTSTATUS | varchar(50) | YES | | NULL | | | STOPPED | varchar(50) | YES | | NULL | | +--------------+-----------------------+------+-----+---------+-------+
- 打印列名:
1
SHOW COLUMNS from CHARTEVENTS;
这个返回结果和
DESCRIBE CHARTEVENTS;是完全一致的。
修改表
- 增加一列 1
1 2
ALTER TABLE table ADD [COLUMN] column_name;
- 删除一列
1 2
ALTER TABLE table_name DROP [COLUMN] column_name;
- 添加索引
1 2
ALTER TABLE table ADD INDEX [name](column, ...);
或
1 2
CREATE INDEX index_name ON table_name (column,...);
- 删除索引
1
DROP INDEX index_name;
- 创建唯一索引
1 2
CREATE UNIQUE INDEX index_name ON table_name (column,...);
- 添加主键
1 2
ALTER TABLE table_name ADD PRIMARY KEY (column_name,...);
- 删除主键
1 2
ALTER TABLE table_name DROP PRIMARY KEY;
- 删除表
1
DROP TABLE [IF EXISTS] table_name;
插入记录
- 插入一行
1
INSERT INTO CHARTEVENTS (FIELD1_NAME, FIELD2_NAME,...) VALUES (FIELD1_VAL, FIELD2_VAL,...)
- 插入多行
1 2 3 4 5
INSERT INTO table_name(column_list) VALUES(value_list1), (value_list2), (value_list3), ...;
如果插入的行中包含了所有列的值,那么column_list可以不用显式给出,如:
1
2
mysql> CREATE TABLE t (qty INT, price INT);
mysql> INSERT INTO t VALUES(3, 50), (5, 60);
上面在进行插入的时候就不用指定列名(即字段名)。
- 批量插入
1 2
INSERT INTO CHARTEVENTS SELECT * FROM OTHER_CHARTEVENTS;
这里也列名也是没有显式指定,是因为SELECT的结果的列名(或字段名)和表CHARTEVENTS是完全一致的,包括列名(字段名)的顺序。
- Python插入
参考https://www.jianshu.com/p/0631443593da
1
更新记录
- 更新表中所有记录
1 2 3
UPDATE table_name SET column1 = value1, ...;
- 根据特定条件更新记录
1 2 3 4
UPDATE table_name SET column_1 = value_1, ... WHERE condition
- 连接更新
1 2 3 4 5 6
UPDATE table1, table2 INNER JOIN table1 ON table1.column1 = table2.column2 SET column1 = value1, WHERE condition;
删除记录
- 删除表中所有记录
1
DELETE FROM table_name;
- 删除符合条件的记录
1 2
DELETE FROM table_name WHERE condition;
- 连接删除
1 2 3 4 5
DELETE table1, table2 FROM table1 INNER JOIN table2 ON table1.column1 = table2.column2 WHERE condition;
建立索引
1
2
3
4
5
ALTER TABLE CHARTEVENTS
ADD INDEX CHARTEVENTS_idx01 (SUBJECT_ID, HADM_ID, ICUSTAY_ID),
ADD INDEX CHARTEVENTS_idx02 (ITEMID),
ADD INDEX CHARTEVENTS_idx03 (CHARTTIME, STORETIME),
ADD INDEX CHARTEVENTS_idx04 (CGID);
给TEXT或BLOB类型字段加索引
由于给TEXT或BLOB类型字段加索引会使得索引特别大,所以一般是对TEXT或BLOB字段的前几位加上所以,如:
1
2
ALTER TABLE CHARTEVENTS
ADD INDEX CHARTEVENTS_idx05 (VALUE(10));
ROW_NUMBER() 函数
ROW_NUMBER()函数是对分组后的查询结果的每行进行编号。一般的用法分为两类:
- 第一类用法
1 2
,ROW_NUMBER() OVER (ORDER BY CHARTTIME) as RN_FIRST ,ROW_NUMBER() OVER (ORDER BY CHARTTIME desc) as RN_LAST
上面查询的意思是说先对字段
CHARTTIME进行从小到大(第一个查询)或倒序排序,然后返回每一行的编号(编号从从返回的第一行开始从1编号,每行一次+1)。 - 第二类用法
1 2
, ROW_NUMBER() OVER (PARTITION BY ICUSTAY_ID ORDER BY CHARTTIME) AS RN_FIRST , ROW_NUMBER() OVER (PARTITION BY ICUSTAY_ID ORDER BY CHARTTIME DESC) AS RN_LAST
这种方式与上面的方法差不多,唯一的区别是加入了
PARTITION BY ICUSTAY_ID。这时候可以解释如下:查询首先根据字段ICUSTAY_ID进行分组,然后在每个组内根据字段CHARTTIME进行排序(正序或反序),最后返回每个组内排序后的每行编号。
这里的最后的结果是每组以ORDER BY CHARTTIME DESC即每组以CHARTTIME倒序(从大到小)返回的,这是因为ORDER BY CHARTTIME DESC在ORDER BY CHARTTIME之后执行。
ROW_NUMBER() OVER (PARTITION BY ...)对数据量很大的表的效率较低。
MySQL 字符串函数
MySQL的字符串函数可以参见2,
SUBSTRING函数
语法:
1
2
3
SUBSTRING(string, start, length)
-- 或者
SUBSTRING(string FROM start FOR length)
其中string和start是必须参数,length是可选参数,如果没有提供,则表示子串的长度一直到原字符串的结尾。
比如:
1
SELECT SUBSTRING("SQL Tutorial", 2, 5) AS ExtractString;
返回的结果是QL Tu, 说明SUBSTRING的start的参数index是从1而不是开始的。
1
SELECT SUBSTRING("SQL Tutorial", -5, 5) AS ExtractString;
start为负数表示从后(右)向前(左)开始计算,返回的结果是orial,说明从右向左的index是从-1开始的,依次为-1, -2, -3,…
REGEXP_SUBSTR函数
SUBSTRING函数是根据子串的起始位置和长度来提取子串。而REGEXP_SUBSTR则是利用正则表达式提取子串。
语法:
1
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
其中expr是原字符串,pat则是正则表达式的子串,基本的用法例如
1
SELECT REGEXP_SUBSTR('Thailand or Cambodia', 'l.nd') Result;
返回land。但是如果有多个匹配的话,默认只返回第一个匹配的值,如
1
SELECT REGEXP_SUBSTR('lend for land', 'l.nd') Result;
这个只返回lend。
多表查询 WHERE 还是 INNER JOIN
多表查询有两种方式:
- 第一种使用
WHERE1 2 3
SELECT A.SUBJECT_ID, A.CHARTTIME, B.LOS FROM CHARTEVENTS A, ICUSTAYS B WHERE A.ICUSTAY_ID=B.ICUSTAY_ID
- 第二种是使用
JOIN1 2 3 4
SELECT A.SUBJECT_ID, A.CHARTTIME, B.LOS FROM CHARTEVENTS A INNER JOIN ICUSTAYS B ON A.ICUSTAY_ID=B.ICUSTAY_ID
多表查询的这两个方式都是返回一样的结果,不同的是:
第一种方式(使用WHERE)实际是SQL引擎首先创建两张表的笛卡尔积,即首先SQL引擎首先将所有可能的组合都先被创建出来。比如如果表CHARTEVENTS和表ICUSTAYS分别有100万行记录,那么SQL引擎首先计算笛卡尔积计算,将两个表所有的组合计算出来,一共就是100万 x 100万行的笛卡尔积结果(大宽表即两个表所以的字段)。然后才是根据WHERE条件进行过滤,比如这里过滤后的记录数为1000,那么SQL引擎就从100万 x 100万的笛卡尔积结果查询出符合条件的1000条记录,并返回需要的字段。显然,笛卡尔积链接是很大问题。
第二种方式(使用INNER JOIN)实际就返回1000条记录,查询效率提高。
INNER JOIN, LEFT JOIN, RIGHT JOIN
INNER JOIN或JOIN是指内连接:返回两个表中字段都匹配且都存在的记录,就是求两个表交集LEFT JOIN左连接:返回左表所有记录,如果右表有对应匹配记录则返回该记录,如果右表没有对应匹配记录则返回NULL。RIGHT JOIN右连接:返回右表所有记录,如果左表有对应匹配记录则返回该记录,如果左表没有对应匹配记录则返回NULL。
如果是要连接3张表,则可以使用:
1
2
3
4
SELECT t1.col, t3.col
FROM table1
join table2 ON table1.primarykey = table2.foreignkey
join table3 ON table2.primarykey = table3.foreignkey
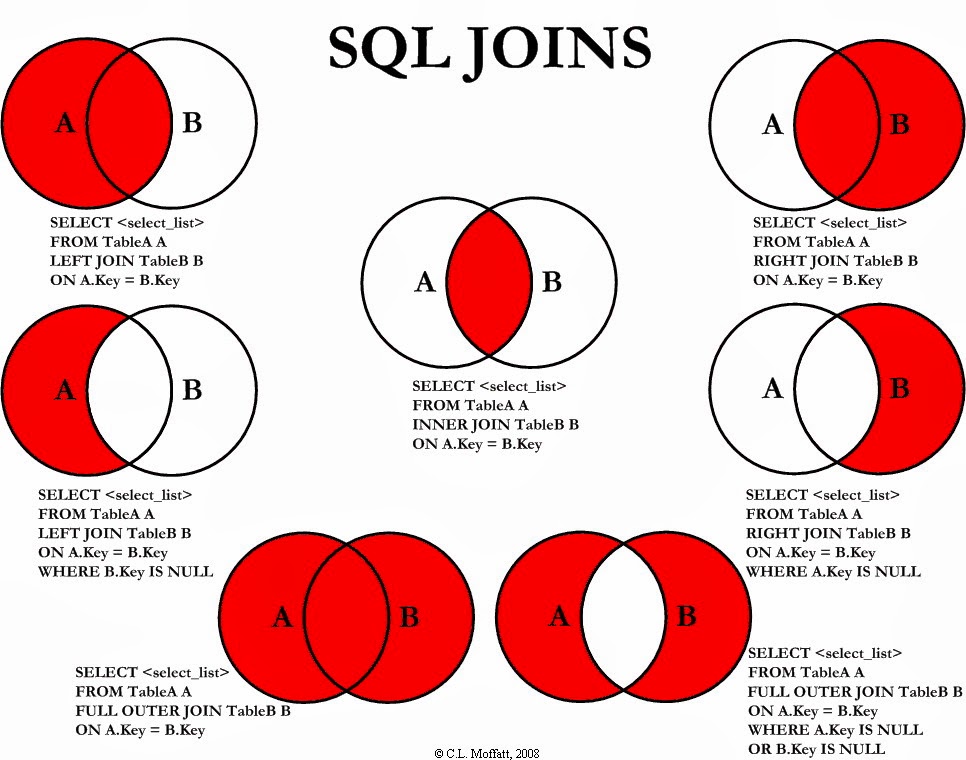 Image from How to join three tables in SQL query – MySQL Example
Image from How to join three tables in SQL query – MySQL Example
UNION连接
UNION将来自多个SELECT语句的结果拼接(按行拼接)到单个结果集中。 结果集列名取自第一个SELECT语句的列名。每个SELECT的结果的列要一一对应。
1
2
3
SELECT ...
UNION [ALL | DISTINCT] SELECT ...
[UNION [ALL | DISTINCT] SELECT ...]
视图
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。作为一个select语句保存在数据字典中的。通过视图,可以展现基表的部分数据;视图数据来自定义视图的查询中使用的表,使用视图动态生成。基表:用来创建视图的表叫做基表base table。
Q:为什么要使用视图?3
A:因为视图的诸多优点,如下:
- 简单:使用视图的用户完全不需要关心后面对应的表的结构、关联条件和筛选条件,对用户来说已经是过滤好的复合条件的结果集。
- 安全:使用视图的用户只能访问他们被允许查询的结果集,对表的权限管理并不能限制到某个行某个列,但是通过视图就可以简单的实现。
- 数据独立:一旦视图的结构确定了,可以屏蔽表结构变化对用户的影响,源表增加列对视图没有影响;源表修改列名,则可以通过修改视图来解决,不会造成对访问者的影响。 总而言之,使用视图的大部分情况是为了保障数据安全性,提高查询效率。
创建视图
1
2
3
4
CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]
VIEW view_name [(column_list)]
AS select_statement
[WITH [CASCADED | LOCAL] CHECK OPTION]
- OR REPLACE:表示替换已有视图
- ALGORITHM:表示视图选择算法,默认算法是UNDEFINED(未定义的):MySQL自动选择要使用的算法 ;merge合并;temptable临时表
- select_statement:表示select语句
[WITH [CASCADED LOCAL] CHECK OPTION]:表示视图在更新时保证在视图的权限范围之内. CASCADED是默认值,表示更新视图的时候,要满足视图和表的相关条件.LOCAL表示更新视图的时候,要满足该视图定义的一个条件即可.
TIPS:推荐使用WHIT [CASCADED|LOCAL] CHECK OPTION选项,可以保证数据的安全性
1
2
3
4
5
6
7
8
9
CREATE VIEW [IF NOT EXISTS] view_name
AS
select_statement;
-- 或者
CREATE OR REPLACE view_name
AS
select_statement;
或者加上 WITH CHECK OPTION:
1
2
3
4
5
6
7
CREATE VIEW [IF NOT EXISTS] view_name
AS select_statement
WITH CHECK OPTION;
-- 或者
CREATE OR REPLACE view_name
AS select_statement
WITH CHECK OPTION;
删除视图
- 删除单个视图
1
DROP VIEW [IF EXISTS] view_name;
- 删除多个视图
1
DROP VIEW [IF EXISTS] view1, view2, ...;
- 重命名视图
1 2
RENAME TABLE view_name TO new_view_name;
- 查看数据库中的视图
1 2 3
SHOW FULL TABLES [{FROM | IN } database_name] WHERE table_type = 'VIEW';
WITH(Common Table Expressions, 公用表表达式)
公用表表达式(CTE)是一个命名的临时结果集或表,存在于单个语句的有效范围内,以后可以在该语句中多次引用。4
语法:
1
2
3
WITH [RECURSIVE]
cte_name [(col_name [, col_name] ...)] AS (subquery)
[, cte_name [(col_name [, col_name] ...)] AS (subquery)] ...
cte_name是单一CTE的名字,这个名字可以在“单个语句的有效范围内”作为TABLE名字呗引用。subquery 被称为 “subquery of CTE”, 它负责产生CTE的结果集。CTE的基本用法如下
1
2
3
4
5
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;
既然CTE可以作为临时表在“单个语句的有效范围内”使用,那么很自然就可以像到CTE是可以显式指明该CTE的列名的,如
1
2
3
4
5
6
7
WITH cte (col1, col2) AS
(
SELECT 1, 2
UNION ALL
SELECT 3, 4
)
SELECT col1, col2 FROM cte;
以下是可能使用到CTE的地方:
- 在
SELECT,UPDATE和DELETE语句前1 2 3
WITH ... SELECT ... WITH ... UPDATE ... WITH ... DELETE ...
- 在
子查询subquery前:1 2
SELECT ... WHERE id IN (WITH ... SELECT ...) ... SELECT * FROM (WITH ... SELECT ...) AS dt ...
- 紧接在含有
SELECT语句之前,如:1 2 3 4 5 6
INSERT ... WITH ... SELECT ... REPLACE ... WITH ... SELECT ... CREATE TABLE ... WITH ... SELECT ... CREATE VIEW ... WITH ... SELECT ... DECLARE CURSOR ... WITH ... SELECT ... EXPLAIN ... WITH ... SELECT ...
触发器
https://www.mysqltutorial.org/mysql-cheat-sheet.aspx
创建触发器
存储过程
创建存储过程
https://www.cnblogs.com/fnlingnzb-learner/p/5865256.html
存储函数 stored functions
创建存储函数
比较函数和基本操作
参考5
| Name | Description | |
|---|---|---|
| > | Greater than operator | |
| >= | Greater than or equal operator | |
| < | Less than operator | |
| <>, != | Not equal operator | |
| <= | Less than or equal operator | |
| <=> | NULL-safe equal to operator | |
| = | Equal operator | |
| BETWEEN … AND … | Whether a value is within a range of values | |
| COALESCE() | Return the first non-NULL argument | |
| GREATEST() | Return the largest argument | |
| IN() | Whether a value is within a set of values | |
| INTERVAL() | Return the index of the argument that is less than the | first argument |
| IS | Test a value against a boolean | |
| IS | NOT Test a value against a boolean | |
| IS NOT NULL | NOT NULL value test | |
| IS NULL | NULL value test | |
| ISNULL() | Test whether the argument is NULL | |
| LEAST() | Return the smallest argument | |
| LIKE | Simple pattern matching | |
| NOT BETWEEN … AND … | Whether a value is not within a range of values | |
| NOT IN() | Whether a value is not within a set of values | |
| NOT LIKE | Negation of simple pattern matching | |
| STRCMP() | Compare two strings |
注意:
在
MySQL 8.0.4及以后版本中,LEAST("11", "45", "2") + 0实际是在计算"11" + 0所以结果是整数11.而在MySQL 8.0.3及之前的版本中,LEAST("11", "45", "2") + 0实际是在计算"2" + 0所以结果是整数2,但是如果是LEAST("11", "45", "2")那么就是按照字符串顺序计算大小值,所以返回的是”11”。以上比较函数的返回结果是
1 (TRUE),0 (FALSE), orNULL.<=>是相等比较,如果比较两边都是NULL则返回1不是NULL;如果两边只有一个是NULL,则返回0而不是NULL.